Property testing does not inspire (my) confidence
In a post, Hillel Wayne misunderstands my argument about (not necessarily against) property-based testing (PBT). My fault for talking about it on twitter. Here I’ll try to start the discussion I’ve been wanting to have for a long time.
Disclaimer: I am often wrong.
History
I’ve been involved, even on occasion academically, in testing since 1981. I keep seeing the same themes popping up. So let’s work through some of them.
As Hillel points out, the following metaphor has problems, but it’s the metaphor people use, so I will too.
You can imagine the set of possible inputs to a program like this. It’s an effectively infinite set.

Just testing random inputs from a huge set seems wrong. A divide-and-conquer approach seems like it would be better. What if we could divide the inputs into partitions (clunky word, but the one academics traditionally use) and test one (or a few) inputs in the partitions? Like this:
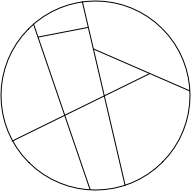
Here are two ways to create the partitions: by focusing on the structure of the problem (or input), and by focusing on the structure of the code.
Structure
I once heard of flight control software that had a bug, discovered in simulation, such that when the plane would have crossed the equator from north to south (to where latitudes are negative), the software would have flipped it upside down. I wouldn’t bet much money that it was a real bug, but it’s certainly a plausible bug because we’re familiar with the idea of negative numbers being importantly different than positive numbers.
You could represent that partitioning this way:

All the values on the bottom have a negative latitude (plus different values for the longitude, airspeed, altitude, and so on). It’d be reasonable to bet any value from the bottom partition would catch the bug. So you’re justified in just picking one, possibly randomly, possibly not, and trying it out.
A disadvantage of such “black box” partition testing is that there’s no obvious principled or automatable way to decide on partitions. “Structure of the inputs” is vague; “structure of the problem” is worse.
But something else has structure: the code. It surely has some relation to the structure of the inputs, and we have lots of tech for dealing with code structure: that’s what compilers do.
And a big part of what compilers do is process branches in the code graph. For example, consider:
line 3432: if a < 0, then: …, else: …
Hey, presto! We have two partitions: the set of inputs such that a is less than zero, and the set of inputs such that a is greater than or equal to zero. It may be hard - as in halting problem hard - to work backwards from those statements to the point of input, but at least it’s a technical problem, not a fuzzy “shape of the problem” one.
Just as appealingly, you get a stopping criterion. Unlike black box testing, where you never know when you’ve enumerated all the relevant partitions, you can easily know when you’ve exercised all the branches. Just a small matter of programming.

Except, as zillions of people have pointed out, there’s no reason to think that “all the branches” are enough.
line 3432: if a < 0, then: …, else: …
line 3433: if b < 0, then: …, else: …
Whereas you can hit ("cover") all the branches with two test inputs (assuming no relationship between a and b), there are actually four paths through those two lines of code. The number of paths through the code grows very big very fast. Back in the day, academics spent a good amount of time developing criteria harder than covering all branches yet easier than covering all paths: for example, leaning on dataflow analysis (something else compilers do!) for criteria like “all paths from a variable assignment to any of the variable's uses.”
Meanwhile…
One of the best exploratory testers I've ever known, Paul "Tall Paul" Czyzewski, once said something like this in a meeting:
Why would I want to test where the bugs aren’t?
That is, the real partitions you want look like these:
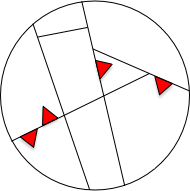
The red triangles represent those partitions where every input reveals the bug. I drew them small because most bugs are not like the flight-control bug, where fully half the inputs would fail.
Intuitively, you want a partitioning method that gives you nothing but small, red partitions. (You don't need to try the other inputs because there are not bugs there.)
Is there a reason to believe partitions formed by covering branches or by property test input combinations are small and red? I don’t think so.
Now, with property tests, additional probes into each partition are roughly free, so maybe that means that random probes within these partitions:
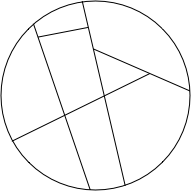
... compensate for how there are no red partitions to target specifically?
A 1990 paper by Hamlet and Taylor, "Partition testing does not inspire confidence" claims not. Based on their simulations, they say that unless your partitions come pretty close to being small and red, randomly probing them is not all that much better than just randomly probing the entire input space.
Notice that Hamlet&Taylor's argument applies to Hillel's example because the simulation doesn't depend on the structure of the code. You need to target small, red partitions to significantly outdo purely random testing, and it doesn't matter if a small red partition comes from a combinatorial explosion where only one specific combination fails or because there's a stray if a == 38363, do: a/0 somewhere in the code.
But…
Every year or so, I bring up Hamlet&Taylor in the context of PBT. I don't think any PBT people have fully engaged with the paper. However, there have been two common responses.
Common errors
PBT test generators are often augmented to favor error-prone values like numerical boundaries, empty strings, empty lists, circular lists, and so on. I interpret that as creating small red partitions within the larger partitions otherwise being probed:
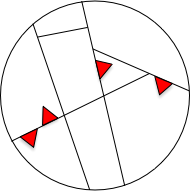
I see such a collection of partitions as giving you a choice.
- You could probe each small red partition manually, just like testers have been doing since the dawn of time. (That is, given that most inputs are multidimensional, like a function with a string and a integer argument, you create tests like “the empty string and 5”, the string “foo” and 0, etc.) The assertion being checked remains the property.
- You use a generator to do the input creation for you. It will create inputs like "the empty string and <some random number>", <some random string> and 0", and so on. Plus various additional inputs, some using the special error values, some not.
If you believe Hamlet&Taylor, that decision essentially comes down to whether writing the generator and property checker is cheaper than writing the tests yourself. (Because the additional generated tests have low expected incremental value.)
I think this is compatible with David R. MacIver's advice for getting started with his PBT tool, which is to start with functions for which it's easy to generate random inputs, flood them with random inputs, and have the property you're testing be "it doesn't crash." Get some amount of benefit for very little cost.
I think that's great. I think MacIver's on the right track - because it's an old, established track. Good testers have always looked for tricks that offer cheap, small wins. I'd be ecstatic if PBT in general were advertised as a supplement to conventional example-based testing, alongside other tricks like, say, pairwise testing (a technique that seems largely forgotten but directly targets combinatorial explosion problems).
However, it's my opinion that too many people describe PBT with the same "one ring to rule them all" technique monomania that's plagued our field forever.
Experience
“But property tests have found a lot of bugs for us.”
Hamlet and Taylor and I might be wrong. But it might also be that you aren't good enough at testing. (Those are not the only two possibilities, but those are the relevant ones for this discussion.)
I'm not willing to accept the "found a lot of bugs" claim unless you've used the resulting bugfixes to investigate and improve your processes (something testers argue for a lot, but doesn't seem to happen often). What have past bugs told you about not making those kinds of bugs in the future? After all, even in the best case you’ve paid someone good money to write the wrong code, then paid someone else good money to rewrite that code.
Coming up, maybe:
- Why property-based testing might be an attractive nuisance, making it hard for programmers to weigh the alternatives.
- Why I prefer using test-driven design to arrive at properties or abstractions, with reference to Euler's polyhedral formula and the great Imre Lakatos.
