Tabular tests in Elixir
I recently read Aleksandr Skobelev's nice "Fundamentals of Optimal Code Style." I like that he uses principles of human perception – how the eye tracks things, how humans read – to produce his suggestions for style. And I especially like that he provides justification for my obsession with tabular tests:
Therefore, for a correct assessment of the overall structure of the program, it is important to form the correct visual structure in the vertical direction.
He shows, for example, the conversion of this:

... to this:
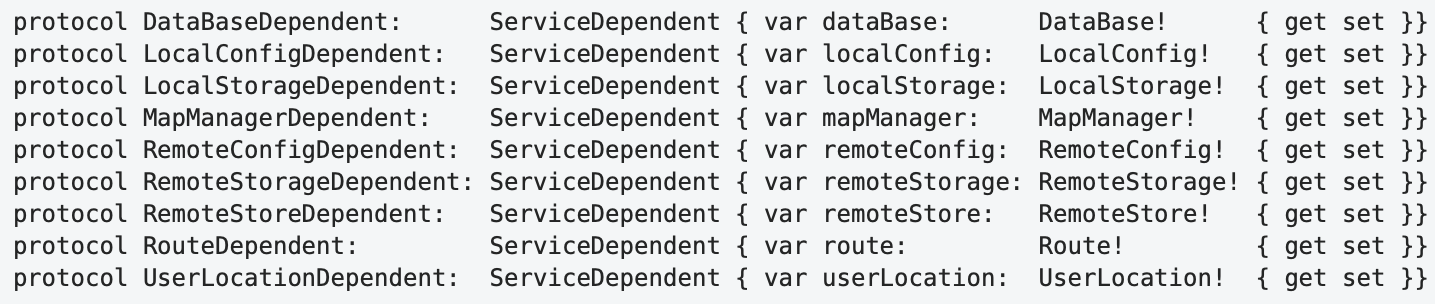
Now clearly defined groups (grouping by "proximity") have been formed in the horizontal direction, and the structure of each definition and the differences between them have been revealed. The way this code is read is also different. After a quick initial familiarization with the structure and identifying common parts, further analysis simply ignores these common parts, and attention is focused only on the different parts. Thus, due to the more active use of ambient vision, the load on the focal vision is reduced and the amount of mental effort required to understand the program is reduced.
I think such vertical scanning is especially important in tests, because people often approach tests not to read them but to skim them, looking for the test that matters or what's different about the different tests.
A simple format
A function named PNode.Previously.parse takes a list with various formats and "normalizes" it into a single structure. I use a table to make the variation immediately visible:

I claim a vertical scan shows the different possibilities well. I grant that I'm more finicky about lining up brackets and such than is strictly needed.
It used to be considered poor style to have this many assertions in a single test, partly because a failure in the first prevents any checking of the later ones. I never agreed with that rule, and I specifically don't want further checking. Very likely any further failures will be noise, producing no additional information.
When doing test-driven design, I'll often write the first test in the usual assert non-tabular style. Then, with the next test, I'll decide whether to convert to tabular style by extracting expect out of the first test. That function looks like this:
test "creation" do
expect = fn arg, expected ->
actual = Pnode.Previously.parse(arg)
assert Pnode.EENable.eens(actual) == expected
end
[insert: :a ] |> ...When functions take more than one argument, I enclose them in a list:
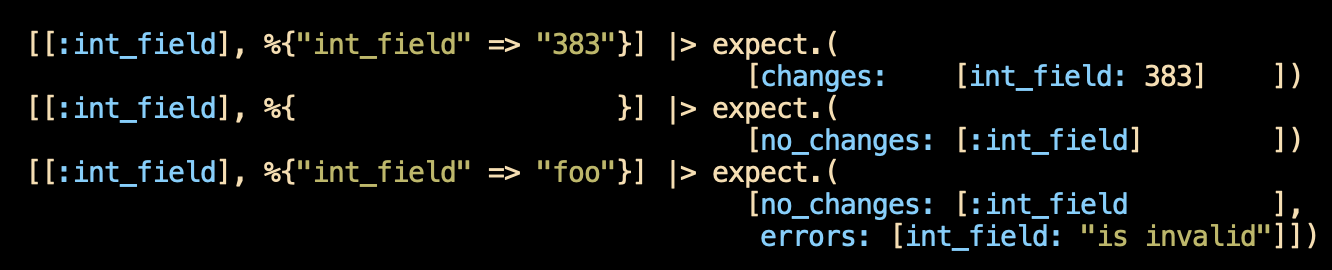
This example is awkward because the table exceeds the maximum line length, so I have to break the lines.
It's true that these lines will probably not make any sense to you without context. That's probably true even if you see the definition of expect:
# We can generate `changeset` notation rather than
# assertions because that's easier to examine.
test "creating and checking, part 1: changeset notation" do
expect = fn [cast_fields, params], expected ->
AsCast.new(cast_fields)
|> ChangesetAsCast.changeset_checks(Schema, params)
|> assert_equal(expected)
end
But I think non-tabular tests would be as obscure. You don't know the program I'm extracting these tests from.
Generators
Writing an expect function is easy enough, and for a long time that's what I did. However, generating the function adds three features that are too much hassle otherwise.
- The vast majority of
expectfunctions will compare with equality. Why writeassert actual == expectedorassert_equal(actual, expected)if you don't have to? We can make it the default. - ExUnit has nice reporting for failed assertions – I prefer it to what you get for other exceptions. The ordinary report:
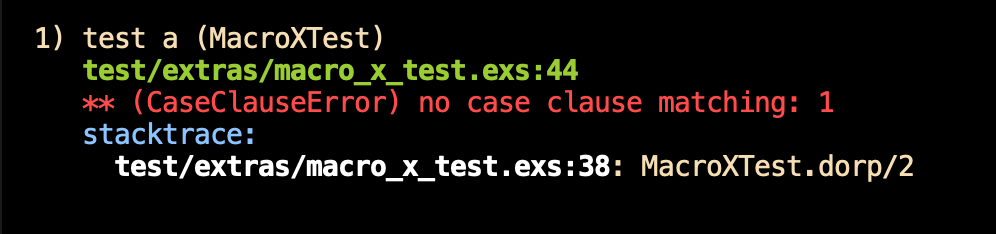
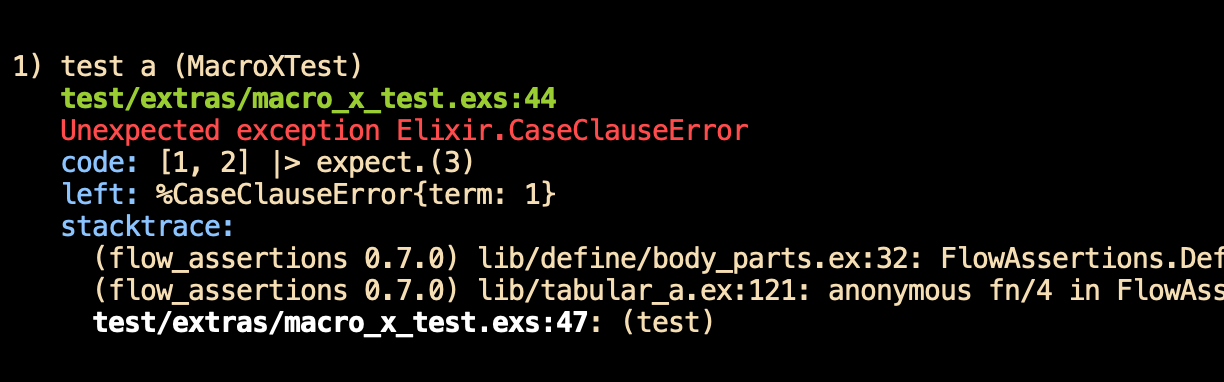
... has a little less information than this:
- If the code under test is expected to throw exceptions in some cases, you have to use the rather bulky
assert_raiseconstruct:
assert_raise(KeyError, "key :a not found", fn ->
TestState.fetch!(:a)
end)
whereas I'd prefer the tabular:
:a |> raises.([KeyError, "key :a not found"])
# or
:a |> raises.(KeyError)
# or
:a |> raises.(~r/key :a/)(The need for brackets in the first case is slightly annoying.)
The generators I use are in the FlowAssertions.Tabular module in my flow_assertions package. Here's an example:
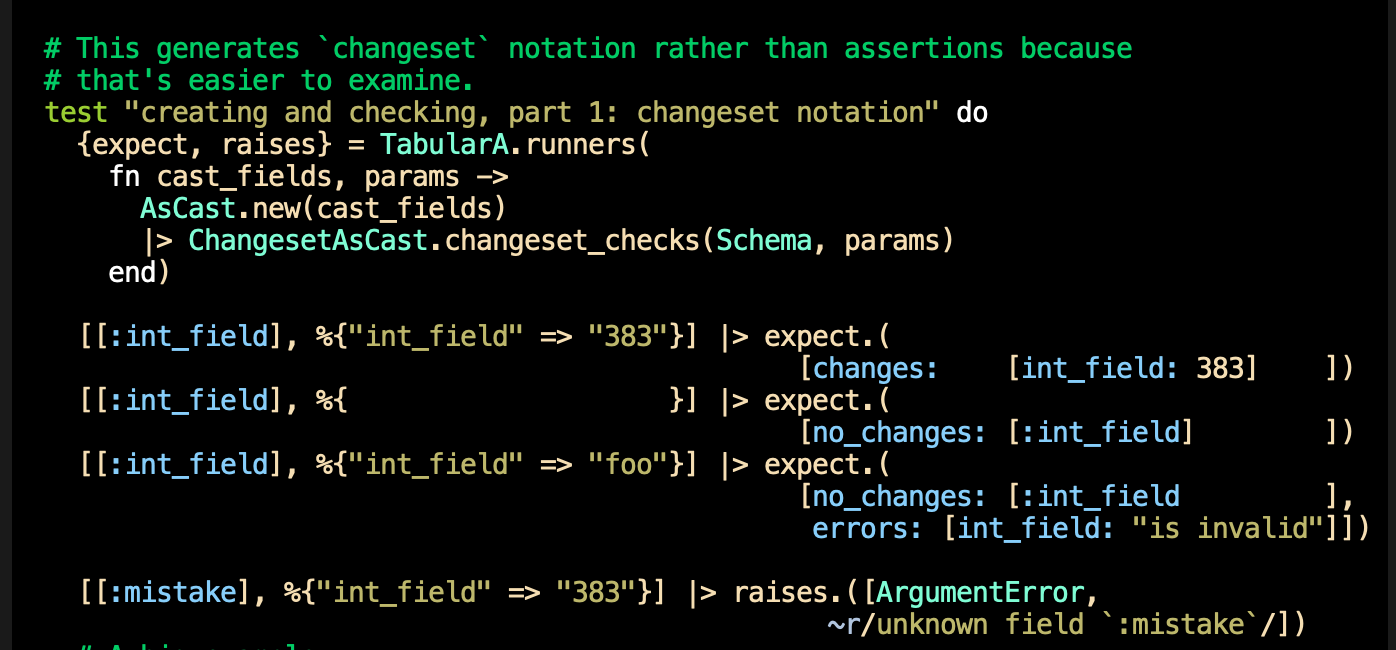
I hope this is of use to you.